


Machine Learning Algorithms. Rule Learner doesn’t limit itself to one particular ML algorithm. It has been designed to apply different ML algorithms and to accept different input/output formats. However, the practical experience shows that two well-known ML algorithms, namely C4.5 and RIPPER, are usually the best choice to produce compact and human understandable classification rules. The current version of Rule Learner utilized the implementation of these algorithms provided by the popular open source machine learning framework “WEKA“.
While there are many ML algorithms and implementation tools, it’s naive to expect that one ML algorithm is an optimal choice for ALL data sets. Experienced ML analyst know that a serious cleaning and tuning of input data is needed. It is also to be expected that different ML algorithms may behave differently on the same data set.
Applied ML algorithms extract classification rules from the training instances to specify the value of the learning attribute such as “Contact Lenses” in our simple example. The generated rules will be placed in the Excel files in the folder “Modeling/rules”.
The file “GeneratedRulesRipper.xls” contains the following decision table in the first “ClassificationRules”, e.g.:
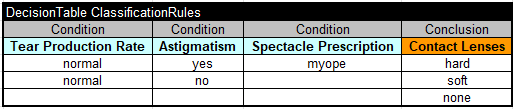
The second tab “ClassificationMetrics” shows more details in the format specific for the selected ML algorithm. For instance, here is the execution protocol for the RIPPER algorithm:
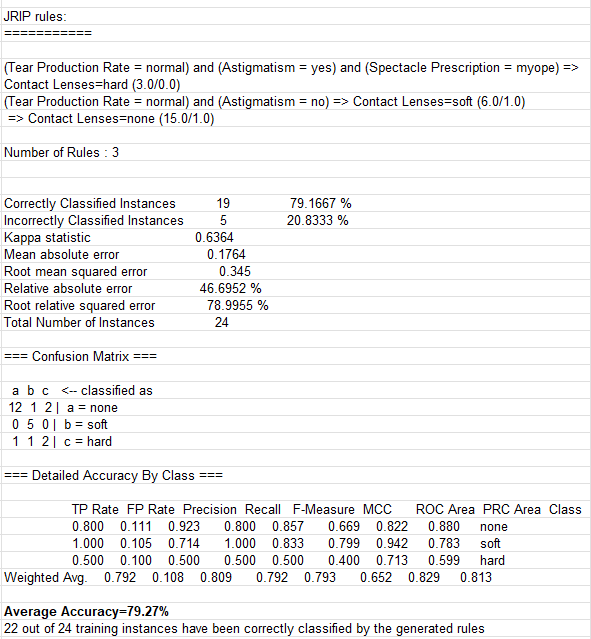
These statistical metrics include the expected percentages of correctly and incorrectly classified instances. These numbers already take into consideration how the learned rules will behave on the new instances, and not how they evaluate the provided training instances. OpenRules added the Average Accuracy=79.27% and the actual numbers of correctly classified training instances (22 our of 24). You can find similar rules and metrics produced by ML algorithm C4.5 in the generated file “GeneratedRulesC45.xls“.
Avoid Over-Fitting and Under-Fitting. The frequently occurred issue with supervised machine learning is that your training set might not be representative enough.
Over-fitting is a key problem when a learning algorithm fits the training data set so well that noise and the peculiarities of the training data play a big role during rules generation. In such situations, the accuracy of learned rules drops when they are tested using unknown data sets. The amount of data used for learning process is fundamental in this context. Small data sets are more prone to over-fitting than large data sets, but unfortunately large data sets can also be affected.
Under-fitting is the opposite of over-fitting and occurs when the ML algorithm is incapable of capturing the variability of the training data.
ML algorithms have a built-in mechanism called cross-validation that helps to avoid these problems. By default, Rule Learner uses the recommended “10-fold cross validation” that became the standard method in many practical situations. However, you always may do some experiments by changing the value 10 to, for example 20, by adding the property “cross.validation=20” (or other value between 2 and 50) in the file “project.properties”.
There are other algorithm-specific properties that could be added in the file “project.properties”. You may read about them in WEKA Book and here are their default values:
- cross.validation=10
- learning.filter=weka.filters.AllFilter
- learning.classifier.options=”-F 3 -N 2.0 -O 2 -S 1″ (for RIPPER)
- learning.classifier.options=”-C 0.25 -M 2″ (for C4.5)
However, if your training instances do not represent the right proportion of different values of the learning attribute, then you could hardly expect an ML classifier learned from that data to perform well on the new examples. One of the practical way to remove some outliers and/or add more representative training instances is to use expert knowledge of the business domain. Rule Learner provides Rule Trainer for doing exactly this by letting your domain experts to represent their knowledge in the form of “training rules” that can filter training instances.

